Gemini 2.0 Flash, an experimental, extremely effective model for developers that offers reduced latency and improved speed, was released in December, ushering in the agentic era. Google AI Studio’s 2.0 Flash Thinking Experimental was upgraded earlier this year, combining Flash’s speed with the capacity to manage highly complicated tasks to improve performance.
All desktop and mobile users of the Gemini app now have access to an upgraded version of 2.0 Flash, which opened up new possibilities to create, communicate, and work with Gemini last week.
Developers may now create production apps using 2.0 Flash thanks to the revised Gemini 2.0 Flash, which is now widely accessible through the Gemini API in Vertex AI and Google AI Studio.
Gemini 2.0 Pro, the best-performing model for sophisticated prompts and coding, has also been made available experimentally in Google AI Studio, the Gemini app, and Vertex AI, for advanced users of Gemini.
The most affordable model to date, Gemini 2.0 Flash-Lite, is now under public preview on Vertex AI and Google AI Studio.
Finally, users of the desktop and mobile versions of the Gemini app will be able to access 2.0 Flash Thinking Experimental through the model dropdown.
All of these models include text output and multimodal input, and future releases will add more features. You can find more information on the Google for Developers blog, including the cost. The Gemini 2.0 family of products will soon receive more upgrades and improved functionality.
2.0 Flash: General Availability Update
The Flash series, which was first introduced at I/O 2024, has grown to be a preferred model among developers due to its effectiveness in handling jobs with high volume and regularity. With a context window of one million tokens, it can manage vast amounts of data and is well-suited for large-scale applications that need for multimodal reasoning. Its qualities have been highly appreciated by the development community.
Through a variety of AI platforms, 2.0 Flash is now available to a larger audience and provides improved performance in important benchmarks. Soon, further features like text-to-speech and picture production will be included.
Gemini 2.0 Flash is available for testing through the Gemini app or the Gemini API in Vertex AI and Google AI Studio. Go to the Google for Developers blog for further information and pricing details.
2.0 Pro Experimental: Our Most Advanced Model for Coding and Complex Prompts
Developers have given insightful input on Gemini 2.0’s capabilities and ideal use cases, particularly for coding activities, through regular updates of early experimental versions, such as Gemini-Exp-1206.
Gemini 2.0 Pro has responded by releasing an experimental version. Compared to earlier iterations, this model exhibits superior reasoning and understanding on general knowledge, as well as the best coding performance and the capacity to handle challenging prompts. It has an extended contextual window of two million tokens, which enables it to efficiently handle and analyze massive amounts of data. It also supports tool integrations like code execution and Google Search.
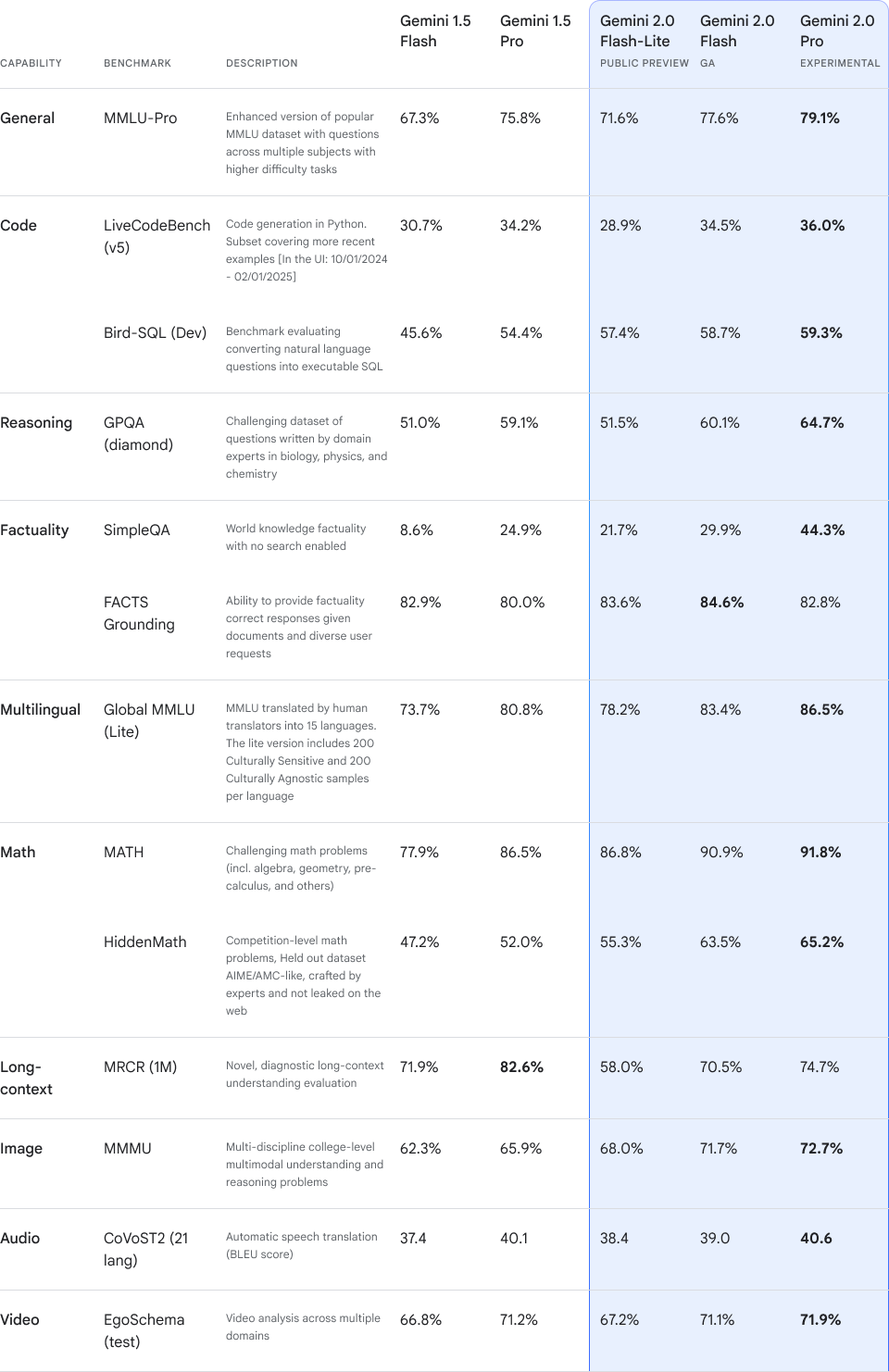
2.0 Flash-Lite: Our Most Affordable Model Yet
Positive comments on 1.5 Flash’s cost and speed prompted more enhancements. The 2.0 Flash-Lite model, which offers higher quality compared to 1.5 Flash without compromising speed or cost, is introduced to retain affordability while improving performance. In most tests, it outperforms 1.5 Flash.
It enables multimodal input and has a context window with one million tokens, much like 2.0 Flash. For example, under Google AI Studio’s premium tier, it can provide a pertinent one-line description for around 40,000 distinct images for less than $1.
The public may now preview Gemini 2.0 Flash-Lite in Vertex AI and Google AI Studio.
Commitment to Safety and Security
Ongoing expenditures are being made to guarantee safe and secure usage as the Gemini model family’s capabilities expand. New reinforcement learning methods, in which the model assesses its answers, are included in the Gemini 2.0 lineup. This results in more accurate feedback and improves the model’s capacity to efficiently handle delicate requests.
Additionally, safety and security hazards are being assessed by automatic red teaming. This involves spotting weaknesses such as non-direct prompt injection, a cybersecurity risk in which harmful instructions are concealed in data that an artificial intelligence machine may access.



Share Your Views: